時系列分析では、定常性という性質を前提として分析が行われるため、前処理として時系列データを定常過程へ変換する必要があります。
このページでは、時系列データの定常性を確認し、非定常性を取り除いていく方法について解説します。
定常性自体については、次のページで解説しています。
定常化処理
時系列データが非定常である場合、諸々の解析を行う前に非定常性を確認して取り除く必要があります。
非定常性にはトレンド、季節性、分散という3つの要素が存在し、この順に非定常性の確認と除去を行います。
これは、データの全体の特徴をより強く表している順番に除去することで、相対的に影響が小さい要素を見つけやすくするためです。
別記事にてRで単位根検定を行ったので、今回はPythonでコードを実行します。
データセットはKaggleのAirPassangersを使用しました。
1949-1960年の米国の旅客機の月間搭乗者数のデータ(Air Passangers)です。
ちなみに、データ(乗客数)に単位がありませんが、以下のデータと比較すると単位は「万人」のようです。
参考文献:AIRLINES GEAR FOR NEW TRANSPORTATION SYSTEM
ちなみにKaggleからダウンロードしなくても同様のデータは以下のコードを実行して入手できます。
import statsmodels.api as sm
sm.datasets.get_rdataset('AirPassengers').dataトレンド非定常性の確認と除去
はじめに可視化を行います。
# データの読み込み
file_path = '../00_data/01_kaggle_Air_Passengers/AirPassengers.csv'
df = pd.read_csv(file_path)
# 年月データを型変換(可視化時のx軸ラベル重複回避)
df['Month'] = pd.DatetimeIndex(df['Month'])
# データの可視化
# df.plot()
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(df['Month'], df['#Passengers'])
ax.set_ylabel('Monthly Number of Airline Passengers')
ax.set_xlabel('Date')
ax.set_title('米国の月間航空機搭乗者数推移(1949-1960年)', fontname = 'MS Gothic')
out_path = '../02_work/02_非定常性確認_除去/02_可視化_搭乗者数推移.png'
fig.savefig(out_path, dpi=150, bbox_inches='tight')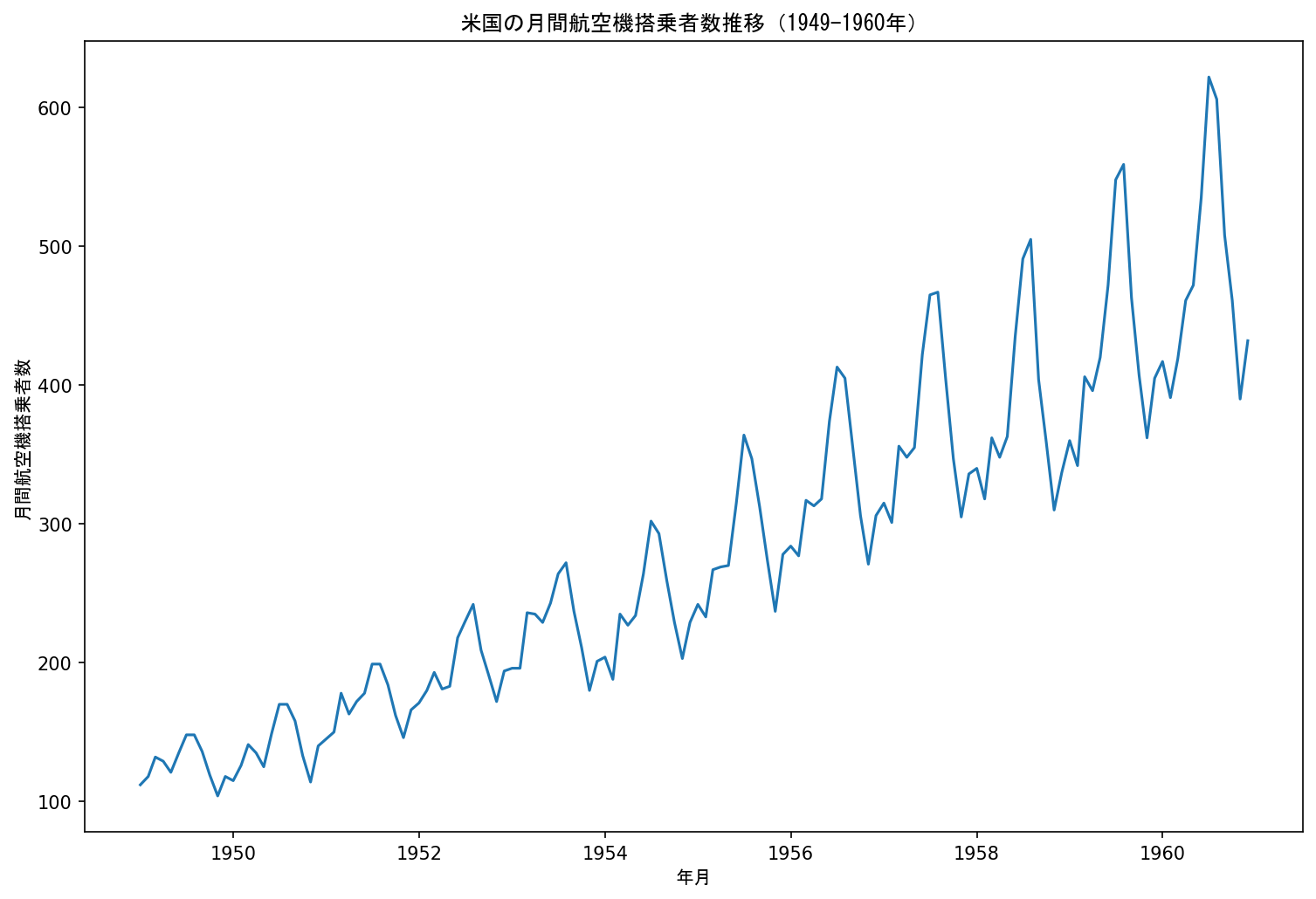
データを見ると明確な上昇トレンドが見られます。
統計的手法でも定常性を確認するためにADF検定を行います。
ADF検定の結果でもp値が十分に大きいため、トレンド非定常性があることがわかります。
# ADF検定(単位根テスト)を実施
adf_out = adfuller(df['#Passengers'])
print(adf_out)
# adf(ADF検定の統計量), p値, モデルに採用されたラグの数, 回帰に使われたデータ数, 1%, 5%, 10%の各信頼区間, 情報量基準の最大値
# (0.815, 0.991, 13, 130, {'1%': -3.482, '5%': -2.884, '10%': -2.579}, 996.693)そこで、トレンド非定常性を除去します。
アプローチとしては、1つ前のデータとの差分(前月比差分)を取得し、それを使用します。
# トレンドの除去
df_diff = df.copy()
# 前月比差分を取得
df_diff['#Passengers'] = df_diff['#Passengers'].diff()
# 1行目はNaNになるので削除
df_diff = df_diff[df_diff['#Passengers'].notnull()]可視化した結果は次のようになりました。
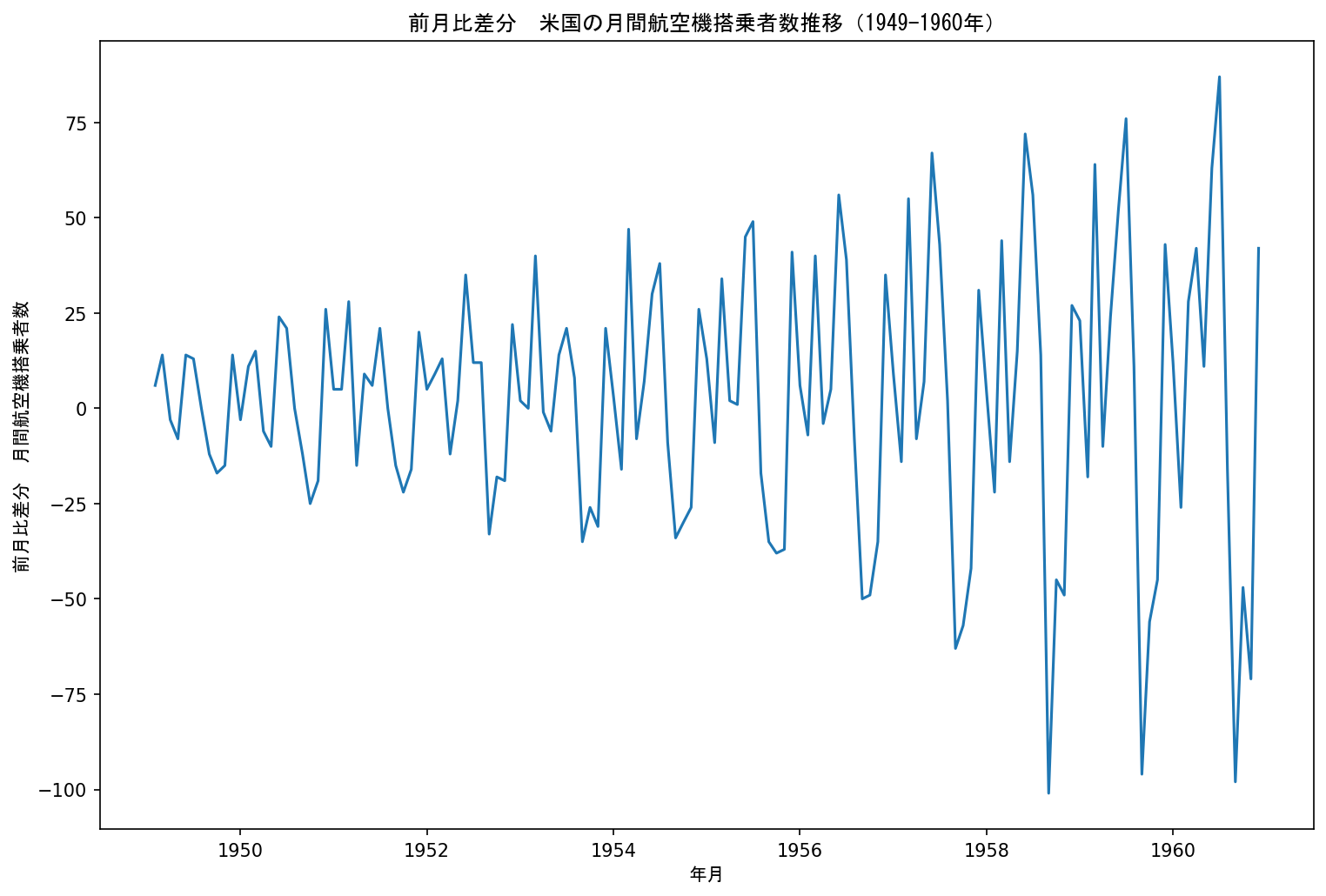
元データの上昇トレンドが除去されているのがわかります。
一方で、季節性と思われる周期的な変動が見られます。
ここで再度ADF検定を行います。
# 前日比差分のデータに対してADF検定(単位根テスト)を実施
adf_out_diff = adfuller(df_diff['#Passengers'])
print(adf_out_diff)
# adf(ADF検定の統計量), p値, モデルに採用されたラグの数, 回帰に使われたデータ数, 1%, 5%, 10%の各信頼区間, 情報量基準の最大値
# (-2.829, 0.054, 12, 130, {'1%': -3.482, '5%': -2.884, '10%': -2.579}, 988.507)ADF検定の結果、p値が0.05を超えているので、季節性を除去します。
季節性非定常性の確認と除去
まず季節成分を抽出・可視化して確認します。
12ヶ月=1年を周期とした季節成分を抽出します。
# 季節成分の抽出
df_seasonal = seasonal_decompose(df_diff['#Passengers'], period=12)
# 季節成分の可視化
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(df_seasonal.seasonal)
ax.set_ylabel('季節成分', fontname = 'MS Gothic')
ax.set_xlabel('時間', fontname = 'MS Gothic')
ax.set_title('季節成分 米国の月間航空機搭乗者数推移(1949-1960年)', fontname = 'MS Gothic')
out_path = '../02_work/02_非定常性確認_除去/02_可視化_搭乗者数推移_季節性.png'
fig.savefig(out_path, dpi=150, bbox_inches='tight')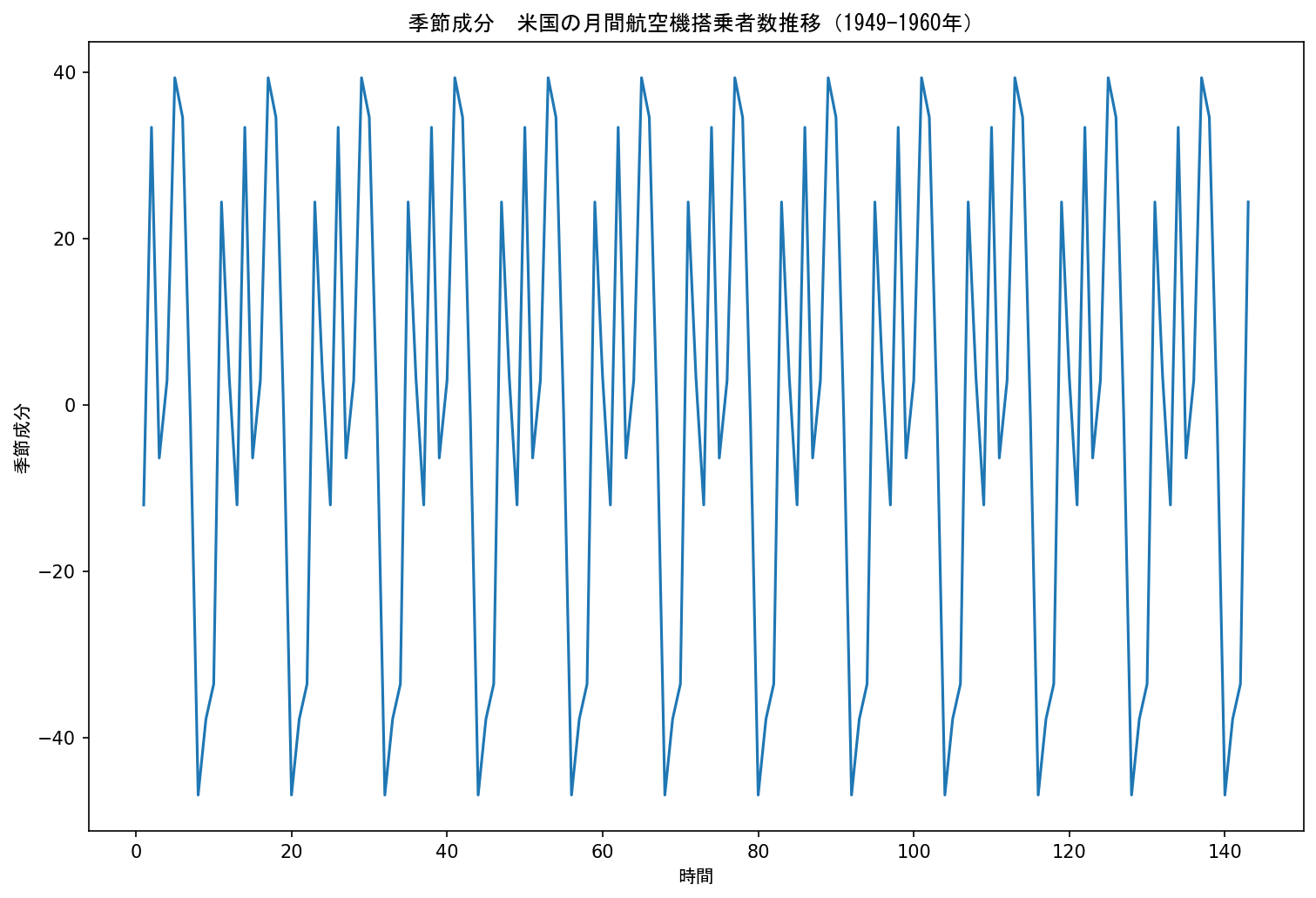
12ヶ月=1年を周期とした季節変動が確認できます。
そこで、季節性を除去します。
df_rmseasonal = df_diff.copy()
# 12ヶ月周期の季節性の除去
df_rmseasonal['#Passengers'] = df_rmseasonal['#Passengers'].diff(12).dropna()
# # 先頭12行はNaNになるので削除
df_rmseasonal = df_rmseasonal[df_rmseasonal['#Passengers'].notnull()]季節性除去後のデータは次のようになりました。
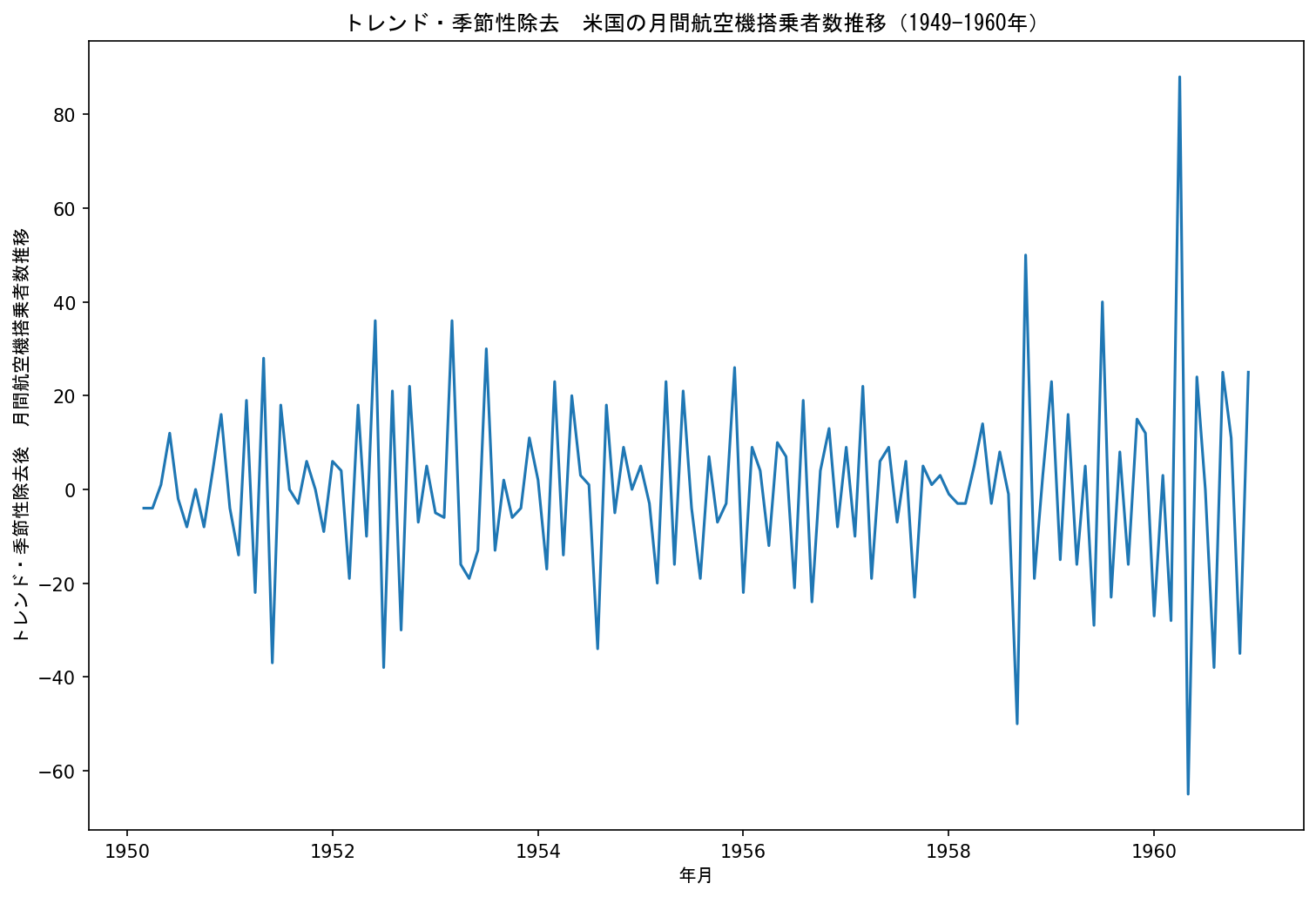
3回目ですがADF検定を行います。
# トレンド・季節性除去後のデータに対してADF検定(単位根テスト)を実施
adf_out_rmseasonal = adfuller(df_rmseasonal['#Passengers'])
print(adf_out_rmseasonal)
# adf(ADF検定の統計量), p値, モデルに採用されたラグの数, 回帰に使われたデータ数, 1%, 5%, 10%の各信頼区間, 情報量基準の最大値
# (-8.098, 1.326e-12, 7, 122, {'1%': -3.485, '5%': -2.886, '10%': -2.580}, 929.165)p値が0.05未満になりました。
これで定常過程と見なせるため本来であればここで終了ですが、学習のために分散非定常性の除去も行います。
分散非定常性の確認と除去
時間推移により分散が変化する時系列データは、分散非定常性があるため定常過程ではありません。
分散が非定常性が見られるデータとして、気象データがあります。
たとえば、雨季には毎日雨や曇りの日がつづくため日射量の分散が小さくなりますが、台風シーズンには大雨の後に台風一過の晴天が広がるなど分散が大きくなります。
このような分散非定常性を除去するには、対数変換やBox-Cox変換を利用します。
Box-Cox変換(べき正規変換)は、正規分布ではないデータの分散を正規分布に近づけるための変換です。
Box-Cox変換は次の式で表せます。
$$ x \longmapsto x^{(\lambda)} = \begin{cases}
\displaystyle \frac{x^\lambda - 1}{\lambda} & \lambda \neq 0\\
\log x & \lambda = 0\end{cases} $$
ここで、元の値 $ x $ は正の値、$ \lambda $ は 0から1の間の数です。
Box-Cox変換は対数変換を一般化したものであり、$ \lambda = 0 $ の時は対数変換、$ \lambda = 0.5 $ の時は平方根変換($ \sqrt{ x } $ への変換)、$ \lambda = 1 $ の時は無変換に相当します。
元の値 $ x $ のとりうる範囲に0や負の値が含まれる場合は、定数を足して正の値に収まるようにしたり、Box-Cox変換を0や負の値に拡張したYeo-Johnson変換を利用します。
トレンド・季節性を除去したAir Passangersのデータに対し、さらに分散の非定常性を除外します。
はじめに、前処理としてBox-Cox変換を行えるようにデータの範囲が正の値におさまるように値を変換します。
# 前処理
# データの最小値が0または負の場合、最小値を加算して正の値に変換
df_boxcox = df_rmseasonal.copy()
min = df_boxcox['#Passengers'].min()
if min <= 0:
df_boxcox['#Passengers'] = df_boxcox['#Passengers'] - min + 1次にBox-Cox変換を行って分散の非定常性を除去します。
df_boxcoxed = df_boxcox.copy()
# Box-Cox変換
df_boxcoxed['#Passengers'], _ = boxcox(df_boxcox['#Passengers'])可視化した結果は次のようになります。
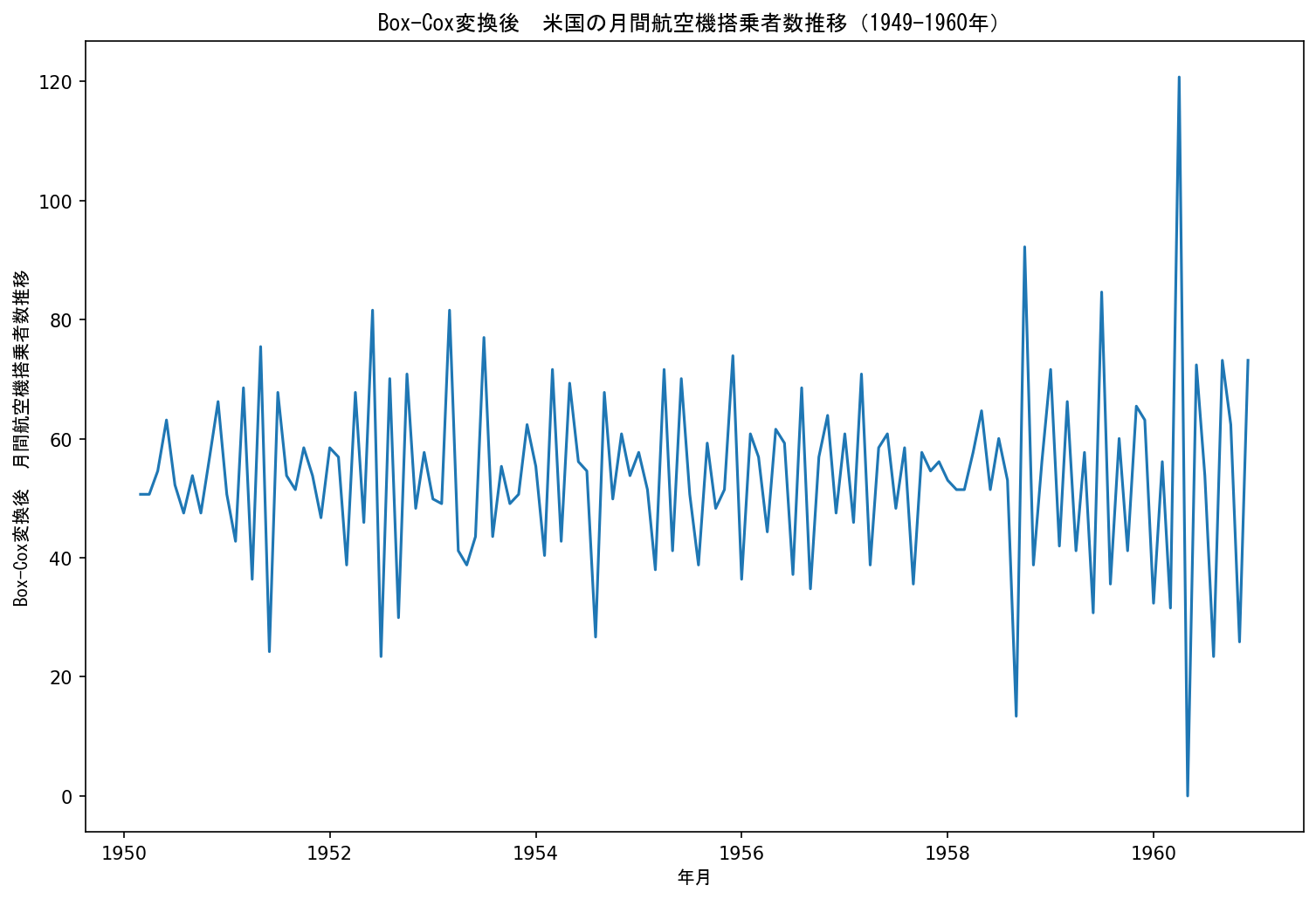
先程のデータ(トレンド・季節性除去後)と見た目はあまり変わりません。
4度目のADF検定を行います。
# Box-Cox変換後のデータに対してADF検定(単位根テスト)を実施
adf_out_boxcoxed = adfuller(df_boxcoxed['#Passengers'])
print(adf_out_boxcoxed)
# adf(ADF検定の統計量), p値, モデルに採用されたラグの数, 回帰に使われたデータ数, 1%, 5%, 10%の各信頼区間, 情報量基準の最大値
# (-7.839, 5.992e-12, 7, 122, {'1%': -3.485, '5%': -2.886, '10%': -2.580}, 875.245)p値は今回も0.05未満になりました。
分散の非定常性を除去する処理を行ってもデータの折れ線グラフとADF検定の結果はどちらも処理前とあまり変わりません。
これは、トレンドと季節性を除去した時点で既に定常過程と見なせる状態であったため、除去すべき非定常性がなかったことが原因です。
今回のデータ(Air Passangers)では、トレンドと季節性の除去で十分であり、分散の非定常性を除去する処理は不要であったと言えます。
事前にわかっていたことですが、今回は学習のために分散の非定常性の処理も実施ました。
実際の分析では、季節性を除去してADF検定のp値が0.05未満になった時点で定常化処理は終了になります。
参考文献
時系列分析の単位根過程、和分過程、ランダムウォークを解説 株式会社AVILEN 2024/5/19閲覧
statsmodels.tsa.stattools.adfuller, Statsmodels 0.15.0 2024/5/19閲覧
北川 徹哉「日最大風速の時系列に含まれる分散不均一性に関する基礎的検討」土木学会論文集A1(構造・地震工学)78 (1) p156-168 (2022)
Box-Cox変換 - PukiWiki 国立看護大学校 研究課程部 看護統計学 2024/5/20閲覧
ボックス=コックス変換 | 統計用語集 統計WEB 2024/5/20閲覧
R. J. Hyndman and G. Athanasopoulos, 予測: 原理と実践 (第3版) 2024/5/19閲覧
曽我部 東馬 「Pythonによる異常検知」オーム社 (2021)