正規表現を使用して数字やカタカナなどを文字種を指定する際には、文字コードの並びの最初と最後の文字を使って「0-9」といった指定の仕方をします。
このページでは、ひらがなやカタカナといった文字種ごとに並び順と指定方法について示します。
正規表現による文字の指定
プログラミング言語で正規表現を使用して文字列の条件抽出を行う際には、数字やカタカナ、漢字といった指定の仕方をすることがあります。
たとえば、「2024-09-01」という日付を表す文字列の中から、数字の部分のみを取り出すコードは、Pythonで次のように書きます。
# 年月日から数字のみを抽出
s = '2024-09-01'
regex = '([0-9]*)-([0-9]*)-([0-9]*)'
yyyymmdd = re.sub(regex, '\\1\\2\\3', s)
print(yyyymmdd)
# 20240901この際、[0-9]*という部分は、0と9の間にある全ての文字列(0123456789)のいずれかに合致する文字が0回以上続くことを表しています。
この際、範囲指定で使用している0と9の間に存在しない文字は条件一致に含まれないため、間違って[1-9]*などと書いてしまうと0が範囲から外れて正しく数字を検出できません。
文字の順番はUnicodeのブロックでの並び順にしたがって正しく最初と最後の文字種を指定する必要があります。
アラビア数字であれば0-9と指定すればよいのですが、ひらがなやカタカナ、漢字などを厳密に全て網羅的に指定する場合は、最初と最後の文字や表記を知っておく必要があります。
以下では、Pythonによる文字種ごとに正規表現による指定方法についてまとめていきます。
ひらがな

上の表はUnicodeの平仮名ブロックの文字コードの一覧表です。
平仮名の並び順は通常の「あ」ではなく、小書き(捨て仮名)の小さい「ぁ」からはじまります。
終わりも「ん」ではなく、合字である「ゟ(より)」が最後になります。
このため、正規表現で「あ-ん」と書いてしまうと、「ぁ」や「ゔ」が指定範囲から外れてしまうため注意が必要です。
Pythonで正規表現を使ったひらがなの指定方法を以下に示します。
通常の文字(例:あ)での表記とコードでの指定(例:\u3042)の2パターンを示します。
また、「ゟ」のような合字は一般的ではないため、「ぁ」から「ん」までの範囲と、平仮名全体での指定方法について記載します。
# ひらがな
# ぁ-ん(ゔを含まない)
print('ぁ-ん')
print('\u3041-\u3093')
# ぁ-ん
# ぁ-ん
# Unicodeブロック:平仮名全体
# ぁ-ゟ
print('ぁ-ゟ')
print('\u3041-\u309F')
# ぁ-ゟ
# ぁ-ゟカタカナ

上の表はUnicodeの片仮名ブロックの文字コードの一覧表です。
片仮名も平仮名同様に通常の「ア」の前に小書き(捨て仮名)の小さい「ァ」がありますが、片仮名ブロックはさらにその前にある「゠」からはじまります。
終わりも「ン」の後に「ヴ」「ヶ」などが続き、最後は、合字である「ヿ(こと)」が最後になります。
このため、正規表現で「ア-ン」と書いてしまうと、「ァ」や「ヴ」「ヶ」が指定範囲から外れてしまいます。
平仮名よりも使用頻度が高い文字が含まれるため、より注意が必要です。
Pythonで正規表現を使ったひらがなの指定方法を以下に示します。
通常の文字(例:ア)での表記とコードでの指定(例:\u30A2)の2パターンを示します。
また、「ヿ」のような合字は一般的ではないため、「ァ」から「ヶ」までの範囲と、片仮名ブロック全体での指定方法について記載します。
片仮名は最初が「゠」で最後「ヿ」なので、片仮名ブロック全体を指定すると片仮名らしい文字が見当たらないことになります。
# カタカナ
# ァ-ヶ(ンヴヵヶを含む)
print('ァ-ヶ')
print('\u30A1-\u30F6')
# ァ-ヶ
# ァ-ヶ
# Unicodeブロック:片仮名全体
# ゠-ヿ
print('゠-ヿ')
print('\u30A0-\u30FF')
# ゠-ヿ
# ゠-ヿ漢字
漢字は、ひらがなやカタカナとは異なり、Unicodeでは複数のブロックに分かれているため、一括で全てを範囲指定することはできません。
しかし、厳密に漢字全てを網羅するわけでなければ、「亜」から「煕」までを指定することで取得できます(JISコード第1・第2水準、Shift-JISでの並び順)。
以下の例では、sの文字列に含まれる様々な漢字がパターンに一致しています。
# 漢字
print('亜-熙')
regex = '([亜-熙]*)'
s = '漢字一覧亜阿哀愛挨姶逢葵茜穐悪握渥旭葦芦朴正煕'
print(re.sub(regex, '\\1', s))
# 漢字一覧亜阿哀愛挨姶逢葵茜穐悪握渥旭葦芦朴正煕ちなみに、regexパッケージを使用することで、UnicodeプロパティのScript値を"Han"と設定することで漢字を指定することもできます。
# regexパッケージを使用
import regex
s = '漢字一覧亜阿哀愛挨姶逢葵茜穐悪握渥旭葦芦朴正煕'
# UnicodeプロパティのScriptの値で指定
p = regex.compile(r'\p{Script=Han}+')
print(p.fullmatch(s)[0])
# 漢字一覧亜阿哀愛挨姶逢葵茜穐悪握渥旭葦芦朴正煕アルファベット(ラテン文字)
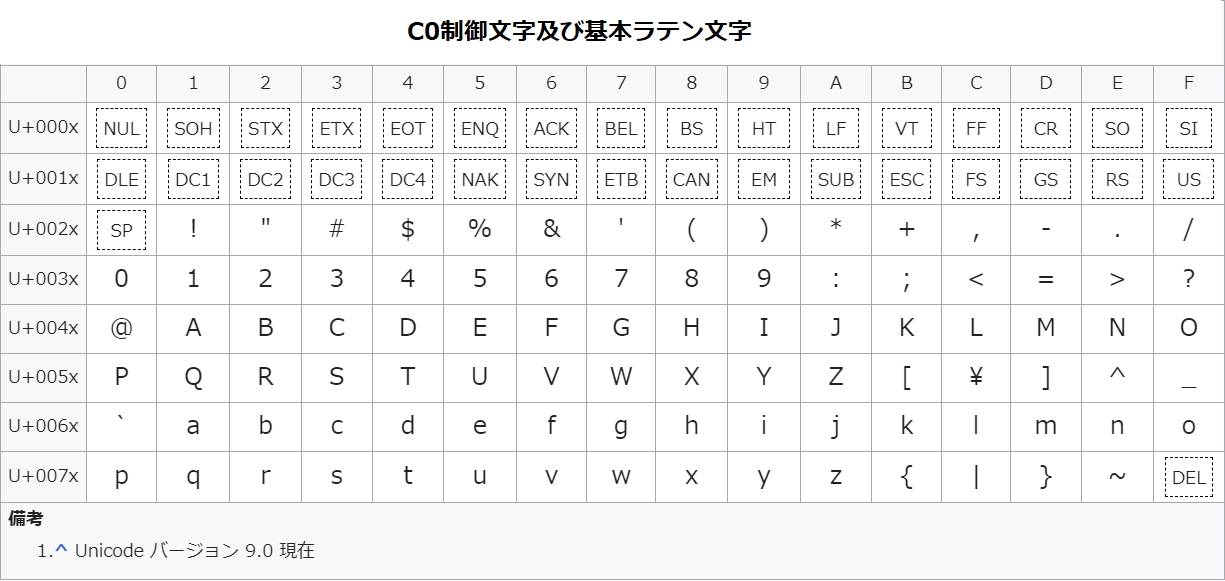
上の表はUnicodeの基本ラテン文字ブロックの文字コードの一覧表です。
基本ラテン文字ブロックには、各種記号やアラビア数字、アルファベットの大文字・小文字の他に、制御文字が含まれます。
アルファベットの大文字と小文字はUnicodeの基本ラテン文字ブロックに分かれています。
そのため、大文字と小文字を指定する際には、以下のように「A-Za-z」といった形で表記します。
以下のコードでは、基本ラテン文字ブロック全体(制御文字を除く)やアルファベットを指定する正規表現を示しています。
# ラテン文字
# 記号を含めた範囲(\u0020は半角スペース)
print('[\u0020-\u007E]+')
# [ -~]+
# 大文字と小文字のアルファベットのみ
print('\u0041-\u005A\u0061-\u007A')
# A-Za-z
# 大文字と小文字の間に記号が配置
print('\u005B-\u0060')
# [-`参考文献
ブロック (Unicode) ウィキペディア 2024/9/17閲覧
正規表現 ウィキペディア 2024/9/17閲覧
Pythonの正規表現で漢字・ひらがな・カタカナ・英数字を判定・抽出・カウント nkmk note 2024/9/21閲覧
平仮名 (Unicodeのブロック) ウィキペディア 2024/9/18閲覧
片仮名 (Unicodeのブロック) ウィキペディア 2024/9/18閲覧
Unicodeで「漢字」の正規表現 ものかの 2024/9/18閲覧
漢字、ひらがな、カタカナにマッチ so-zou.jp 2024/9/18閲覧
基本ラテン文字 (Unicodeのブロック) ウィキペディア 2024/9/18閲覧