高校地理では各都市の気候を可視化する方法として、雨温図とハイサーグラフが使われます。
このページでは、Pythonのライブラリであるmatplotlibを使用して雨温図とハイサーグラフを作成する方法を紹介します。
気候の可視化
観測地点ごとの気候の特徴を定量的に調べる方法として、気温と降水量の2つの気候因子がよく使われます。
世界各地の気候を分類した代表的な気候区分であるケッペンの気候区分においても、月平均気温と月合計降水量という2つの指標を使って気候を分類しています。
しかし、毎月の気温と降水量を表に並べても観測地点ごとの特性をつかみづらいため、適切な可視化を行う必要があります。
月ごとの気温と降水量を可視化する方法として、雨温図とハイサーグラフがあります。
どちらも月平均気温と月合計降水量を可視化したものですが、可視化の方法が異なります。
どちらも同じ情報を可視化しているため方法の違いは本質的なものではありません。
そのため、一般的には雨温図とハイサーグラフは区別されておらず、用語が混同して使われています。
しかし、高校地理では慣例的に雨温図とハイサーグラフを区別しているため、以下では高校地理の定義で雨温図とハイサーグラフを紹介します。
雨温図
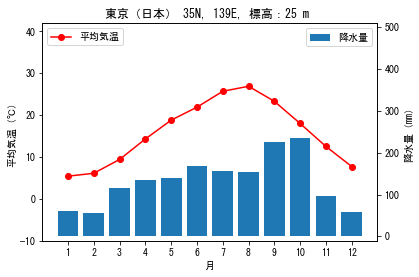
観測地点の月別の平均気温と降水量の分布を可視化したグラフを雨温図といいます。
雨温図では、平均気温には折れ線グラフ、降水量には棒グラフを使用し、1つのグラフとして描画します。
ハイサーグラフ
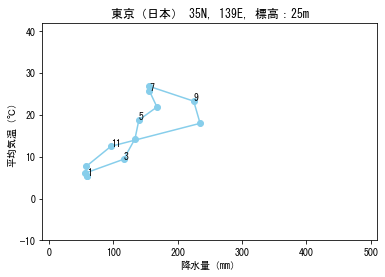
縦軸に平均気温、横軸に降水量をプロットし、月次推移を折れ線でつないだグラフをハイサーグラフといいます。
ハイサーグラフでは、月ごとの値をプロットし、12月→1月も含めて隣り合う月同士を線でつなぐことで気候の季節変化を視覚的に捉えることができます。
先述の雨温図と同じ情報を可視化していますが、季節変化の大きさや年較差(年間の気温や降水量の変化幅)を視覚的に把握しやすいです。
データの取得
雨温図やハイサーグラフを作成するために必要な月平均気温と月降水量のデータは、以下のサイトから取得しました。
年ごとの変動を考慮するために月ごとの平年値を使用します。
世界の天候データツール(ClimatView 月統計値) 気象庁 2024/3/9閲覧
このサイトでは、世界各地の都市(観測地点)について、月平均気温と月降水量を掲載しています。
1991年から2020年までの30年間の平均から算出した平年値を利用します(2024/3/9現在)。
前処理
ダウンロードしたデータから可視化に使用する情報(平年値の気温と降水量)のみを取得します。
同時に表記の修正などの前処理も行います。
2つの関数に分けています(観測地点情報取得とテーブルデータの抽出)。
1つの目の関数は、読み込んだファイルから観測地点情報取得を取得する関数です。
国名・観測地点名などの表記の整理を行った上で、観測地点名・国名・緯度・経度・標高を出力しています。
# 関数定義:観測地点情報取得
def get_info(file):
# 地点情報を取得
df_head = pd.read_csv(file, encoding='cp932')
head_cols = df_head.columns.tolist()
city, country, lat, lon, height = head_cols[2], head_cols[3], head_cols[4], head_cols[5], head_cols[6]
# 都市名のカッコつき表記について修正対応
if (country=='日本')&('(' in city): # 日本国内(都市名の訓読みは削除)
regex = '([^(]*)([ア-ン]*)'
city = re.sub(regex, '\\1', city)
if ('〔' in city): # 中国やソウル特別市など(カギカッコ内に補足情報)
regex = '([^〔]*)〔.*〕'
city = re.sub(regex, '\\1', city)
# 経緯度と高度を簡略表記
# 緯度
regex = '緯度:([0-9]*)\.[0-9]*([N|S])'
lat = re.sub(regex, '\\1\\2', lat)
# 経度
regex = '経度:([0-9]*)\.[0-9]*([E|W])'
lon = re.sub(regex, '\\1\\2', lon)
# 高度
regex = '高度:([0-9]*) .*'
height = re.sub(regex, '\\1m', height)
# 都市名にファイル名に適さない記号がある場合は置き換え
# city = city.replace('/', '-')
# 長い表記を変換
country = country.replace('中華人民共和国', '中国')
country = country.replace('大韓民国', '韓国')
country = country.replace('朝鮮民主主義人民共和国', '北朝鮮')
country = country.replace('アメリカ合衆国(アラスカ)', 'アメリカ合衆国')
country = country.replace('デンマーク・フェロー諸島', 'デンマーク') # フェロー諸島のデータが無い前提で変換
country = country.replace('スイス・リヒテンシュタイン', 'スイス') # リヒテンシュタインのデータが無い前提で変換
country = country.replace('.1', '') # 一部データに存在する".1"を削除
city = city.replace('ヒースロー国際空港', 'ロンドン')
city = city.replace('ベルリン - ダーレム', 'ベルリン')
# スラッシュで区切って複数の都市名がある場合は後ろを削除
regex = '([^/])\/(.*)'
city = re.sub(regex, '\\1', city)
# 「国際空港」の施設名部分を削除
regex = '(.*)国際空港'
city = re.sub(regex, '\\1', city)
# ドット以下の余計な情報の部分を削除
regex = '(.*)・.*'
city = re.sub(regex, '\\1', city)
return city, country, lat, lon, height2つ目はの関数は、ダウンロードしたデータから必要な平年値情報のみを取得する関数です。
気象庁のHPからダウンロードしたファイルからテーブルデータを抽出し、可視化に使用する平年値情報のみを抽出します。
CSVとして出力する際には、1つ目の関数で取得した観測地点情報を出力ファイル名に使用しています。
# 関数定義:気象情報のCSVから必要な情報を取得
def get_table(file):
print(file)
# ファイルから格納フォルダ名取得
regex = '.*01_気象庁_ClimatView_月統計値.([0-9]{2}_.*).climat_[0-9]*.*.csv'
dirname = re.sub(regex, '\\1', file)
# 観測地点情報取得
city, country, lat, lon, height = get_info(file=file)
print(city, country, lat, lon, height)
# データの読み込み
use_cols = [
# '年',
'月',
# '月平均気温', '月平均最高気温', '月平均最低気温', '月降水量',
'月平均気温平年値', '月平均降水量平年値',
# '標準化降水指数(3か月)', '標準化降水指数(6か月)', '標準化降水指数(12か月)'
]
df = pd.read_csv(file, header=1, usecols=use_cols, encoding='cp932')
# 不要行削除
df = df[df['月平均気温平年値']!='(℃)']
# データに欠損がある場合ははじくために、数値をfloatとして読み込む
df['月平均気温平年値'] = df['月平均気温平年値'].astype('float')
df['月平均降水量平年値'] = df['月平均降水量平年値'].astype('float')
df['月'] = df['月'].astype(int)
# 月平均は変わらないのでユニーク化
df = df.drop_duplicates().sort_values('月', ascending=True)
if (df.shape[0]!=12):
display(df)
raise ValueError('月別平年値を取得しようとした結果、行数が12になりませんでした。確認して下さい。')
print(df.columns)
display(df)
# データに欠損がある場合ははじく
df_na = df[(df['月平均気温平年値'].isna())|(df['月平均降水量平年値'].isna())]
if (df_na.shape[0]>0):
print(file)
raise ValueError('データに欠損があります。確認して下さい。')
# テーブルの出力
out_path = f'../02_work/01_気象情報平年値/{dirname}/01_気象情報平年値_{country}_{city}_{lat}_{lon}_{height}.csv'
df.to_csv(out_path, index=False, encoding='cp932')実装
観測地点ごとの月平均気温と月降水量の平年値のCSVを読み込んで、雨温図とハイサーグラフをそれぞれ作成します。
使用したPythonのライブラリは以下のとおりです。
import pandas as pd
import matplotlib.pyplot as plt
import re
import glob
import math
# グラフの日本語文字化け修正用にフォント設定
plt.rcParams['font.family'] = "MS Gothic"雨温図の作成
はじめに、雨温図を作成する関数を示します。
# 関数定義:雨温図作成
def viz_climo(df, city, country, lat, lon, height, kubun):
fig, ax = plt.subplots()
ax2 = ax.twinx()
ax.plot(df['月'], df['月平均気温平年値'], 'o-', color='red')
ax2.bar(df['月'], df['月平均降水量平年値'])
# グラフの表示順の調整
ax.patch.set_visible(False)
ax.set_zorder(1)
xlab = '月'
ylab = '平均気温(℃)'
ylab2 = '降水量(mm)'
title = f'{city}({country}) {lat}, {lon}, 標高:{height[:-1]} m '
ax.set_xlabel(xlab)
ax.set_ylabel(ylab)
ax2.set_ylabel(ylab2)
ax.set_title(title)
# 軸範囲
# 平均気温
ax.set_ylim(-10, 42)
min_temp = df['月平均気温平年値'].min()
if (min_temp<-10):
# 月平均最低気温が-10を下回る月がある場合
ymin = math.floor(min_temp/10)*10
ax.set_ylim(ymin, 42)
# 降水量
ax2.set_ylim(-10, 510)
max_rain = df['月平均降水量平年値'].max()
if (max_rain>500):
# 月降水量が500mmを超える月がある場合
ymax = math.ceil(max_rain/100)*100
ax2.set_ylim(-10, ymax)
# x軸では全ての月を表示
ax.set_xticks(df['月'][::1])
ax.legend(['平均気温'], loc='upper left')
ax2.legend(['降水量'], loc='upper right')
# 出力
save_path = f'../02_work/02_雨温図/{kubun}/02_雨温図_{country}_{city}.png'
fig.savefig(save_path, bbox_inches='tight')
# グラフの表示
plt.show()ハイサーグラフの作成
次にハイサーグラフを作成・出力する関数を示します。
# 関数定義:ハイサーグラフの作成
def viz_hyther(df, city, country, lat, lon, height, kubun):
fig, ax = plt.subplots()
# 各月のデータポイントに月名のラベルを付ける
for i, txt in enumerate(df['月'].astype(str)):
# 全ての月でラベルをつけると見えづらいため奇数月のみつける(0はじまりなのでi=0は1月)
if (i%2==0):
plt.text(df['月平均降水量平年値'][i], df['月平均気温平年値'][i], f'{txt}')
# 12月と1月をつなぐために、dfの最後に1月のデータを追加
df_jun = df[df['月']==1]
df = pd.concat([df, df_jun], axis=0)
ax.plot(df['月平均降水量平年値'], df['月平均気温平年値'], 'o-', color='skyblue')
ylab = '平均気温(℃)'
xlab = '降水量(mm)'
title = f'{city}({country}) {lat}, {lon}, 標高:{height}'
ax.set_xlabel(xlab)
ax.set_ylabel(ylab)
ax.set_title(title)
# 軸範囲
# 平均気温
ax.set_ylim(-10, 42)
min_temp = df['月平均気温平年値'].min()
if (min_temp<-10):
# 月平均最低気温が-10を下回る月がある場合
ymin = math.floor(min_temp/10)*10
ax.set_ylim(ymin, 42)
# 降水量
ax.set_xlim(-10, 510)
max_rain = df['月平均降水量平年値'].max()
if (max_rain>500):
# 月降水量が500mmを超える月がある場合
ymax = math.ceil(max_rain/100)*100
ax.set_xlim(-10, ymax)
# 出力
save_path = f'../02_work/03_ハイサーグラフ/{kubun}/03_ハイサーグラフ_{country}_{city}.png'
fig.savefig(save_path, bbox_inches='tight')
# グラフの表示
plt.show()関数実行・出力
最後に、先ほど作成した雨温図やハイサーグラフを作成する関数を呼び出して、観測地点ごとに雨温図とハイサーグラフを作成します。
なお、途中で出てくるget_kubun関数は、気温と降水量のデータからケッペンの気候区分の分類を返す関数です。
詳細については、こちらのページで解説しています。
# データ取得
glob_path = '../02_work/01_気象情報平年値/*/01_気象情報平年値_*.csv'
files = glob.glob(glob_path)
# 観測地点(ファイル)ごとに可視化を実行
for file in files:
# 観測地点情報取得
regex = '.*01_気象情報平年値_([^_]*)_([^_]*)_([^_]*)_([^_]*)_([^_]*).csv'
country = re.sub(regex, '\\1', file)
city = re.sub(regex, '\\2', file)
lat = re.sub(regex, '\\3', file)
lon = re.sub(regex, '\\4', file)
height = re.sub(regex, '\\5', file)
print(city, country, lat, lon, height)
# dfの読み込み
df = pd.read_csv(file, encoding='cp932', dtype={'月':int})
print(df.columns)
display(df.head(2))
# 気候区の判定
kubun = get_kubun(df, lat)
print(f'気候区:{kubun}')
# 雨温図の作成
viz_climo(df, city, country, lat, lon, height, kubun)
# ハイサーグラフ作成
viz_hyther(df, city, country, lat, lon, height, kubun)参考文献
地理用語研究会編「地理用語集第2版A・B共用」山川出版社(2019)
雨温図(うおんず)とは? コトバンク 百科事典マイペディア 2024/3/20閲覧
ハイザーグラフとは? コトバンク 改訂新版 世界大百科事典 2024/3/20閲覧
ケッペンの気候区分 ウィキペディア 2024/3/16閲覧
ハイサーグラフ ウィキペディア 2024/3/21閲覧
世界の天候データツール(ClimatView 月統計値) 気象庁 2024/3/9閲覧