このページでは、人流データ(スマホ位置情報データ)を使って、ユーザーの滞在場所を抽出し、特定の施設を訪問したかを判定する方法を紹介します。
ユーザーの滞在地点と当該施設の距離を測定し、一定閾値以下であれば当該施設に滞在したと判定します。
これらの処理について、Pythonのコードとともに説明します。
ユーザーの滞在地点判定
人流データを分析する際に、ユーザーがどの場所を訪問したかを確認したいことがあります。
しかし、単に位置情報がある地点を「訪問」と判定してしまうと、その日通った場所が全て滞在と判定されてしまいます。
このような判定の仕方をすると、東京から大阪まで車で移動したユーザーは、通過しただけの静岡や愛知も全て訪問と判定されてしまいます。
このようなやり方では、寄り道してコンビニや道の駅に立ち寄ったとしても、目の前を通り過ぎただけの場所と区別できません。
そこで、「半径〇〇km以内に〇〇分以上位置情報が連続して記録されている場合」のみ、滞在と判定します。
このように半径と継続時間の2つを変数として設定することで、ユーザーの滞在場所を特定できます。
このようなやり方で滞在場所を判定できる関数として、Pythoのscikit-mobilityパッケージのskmob.preprocessing.detection.stay_locationsという関数があります。
scikit-mobilityパッケージは位置情報の取り扱いに役立つPythonのパッケージであり、位置情報の異常値削除や滞在場所判定などに役立つ関数が含まれています。
実装例
ここでは、スマホから取得した人流データを読み込み、ユーザーの滞在地点を判定するコードについて掲載しています。
人流データは、iPhoneのGPS2CSVアプリを使って記録したデータを使いました(参考:GPS2CSVアプリで位置情報を取得)。
import pandas as pd
import re
import folium # 地図上へのマッピング用
import skmob
from skmob.preprocessing import detection # 滞在場所検出
# 位置情報データ読み込み
file_path = '../00_data/GPS_241109_SJIS_LF.CSV'
df_raw = pd.read_csv(file_path, encoding='cp932')
# 前処理
df = df_raw.copy()
# 日付と時刻を結合
df['datetime'] = '20' + df['日付'] + ' ' + df['時刻']
df['datetime'] = pd.to_datetime(df['datetime'])
# 抽出する時間範囲
start = '2024-11-09 09:45:00'
end = '2024-11-09 12:00:00'
dt_start = pd.to_datetime(start)
dt_end = pd.to_datetime(end)
# 時間範囲でフィルタリング
print('抽出前行数:', df.shape[0])
df = df[(df['datetime'] >= dt_start) & (df['datetime'] <= dt_end)]
print('抽出後行数:', df.shape[0])
# あらかじめpandas.DataFrameをTrajDataFrameに変換
tdf = skmob.TrajDataFrame(df, latitude='緯度', longitude='経度', datetime='datetime')
# パラメータの指定
cf_stoptime = 10 # 分
cf_radius = 0.2 # km
# 滞在地点判定
stdf = detection.stay_locations(
tdf,
stop_radius_factor=0.5,
minutes_for_a_stop=cf_stoptime, # 〇〇分以上居ると滞在判定
spatial_radius_km=cf_radius, # 半径〇〇km以内に居続けると滞在判定
leaving_time=True # 滞在地点を出る時間をカラムとして追加するか
)以上のコードを実行すると、以下のようなデータが得られます。
表 stay_locations関数を使用して検出した滞在地点のデータ
| lat | lng | datetime | leaving_datetime | |
| 0 | 35.6593 | 139.7023 | 2024/11/9 9:45:00 | 2024/11/9 10:03:12 |
| 1 | 35.6594 | 139.702 | 2024/11/9 11:05:56 | 2024/11/9 11:20:15 |
| 2 | 35.6667 | 139.7593 | 2024/11/9 11:23:38 | 2024/11/9 11:53:00 |
距離測定による滞在判定
次に、検出した滞在地点と施設の距離を測定し、ユーザーがそれぞれの施設に滞在したかを判定します。
今回は、鉄道駅の位置情報データと人流データを組み合わせ、ユーザーの滞在地点と鉄道駅の距離を測定し、ユーザーが鉄道駅に滞在したかを判定します。
鉄道駅の位置情報は、国土数値情報の鉄道時系列データから取得しました。
以下のコードでは、駅データのシェープファイルを読み込み、距離測定用の前処理を行っています。
カラム名は英数字の番号で表記されているため、国土数値情報のページを参照してカラム名を修正します。
import pandas as pd
import geopandas as gpd
import skmob
# 駅情報データ
file_path = '../../00_common_data/01_国土数値情報/02_鉄道ライン/2023/N05-23_GML/N05-23_Station2.shp'
# シェープファイルの読み込み
gdf = gpd.read_file(file_path, encoding='shift-jis')
# カラム名を修正
gdf = gdf.rename(columns={
'N05_001':'事業者種別', 'N05_002':'路線名', 'N05_003':'運営会社', 'N05_004':'供用開始年', 'N05_005b':'設置期間(設置開始)', 'N05_005e':'設置期間(設置終了)', 'N05_006':'関係ID', 'N05_007':'変遷ID', 'N05_008':'変遷備考', 'N05_009':'備考', 'N05_011':'駅名',
})
# 前処理
tdf_sta = skmob.TrajDataFrame(gdf, latitude='lat', longitude='lng')
tdf_sta = tdf_sta.rename(columns={'lon':'lng'})距離測定にはgeodesic関数を使用します。
この関数を使用すると、経度・緯度から一気にユークリッド距離を測定でき、個別に座標変換を実装する必要がありません。
注意点としては、Pointは経度、緯度の順で表記するのに対し、geodesic関数へ入れる際は、緯度、経度の順で入れることです。
# 距離測定用
from shapely.geometry import Point, LineString, Polygon
from geopy.distance import geodesic
# 関数定義:滞在地点1点に対して駅マートの各駅に対して距離計算を実施し、最寄り駅と距離を返す
def calc_dist(stay_loc, df_spot, geometry_col):
'''
stay_loc: Point, ユーザーの滞在地点1点の座標
df_spot: DataFrame, 駅の位置情報データ
geometry_col : str, 座標データのカラム名
'''
# 距離測定用前処理
df_spot['経度緯度'] = df_spot.apply(lambda x: Point(x['lng'], x['lat']), axis=1)
# 距離測定
df_spot['distance'] = [geodesic((stay_loc.y, stay_loc.x), (spot_loc.y, spot_loc.x)).meters for spot_loc in df_spot['経度緯度']]
ic(df_spot['distance'])
# 最小値とそのindex取得
min_dist = df_spot['distance'].min()
min_idx = df_spot['distance'].idxmin()
# 最寄り駅取得
min_sta = df_spot.loc[min_idx, '駅名']
return min_sta, min_distユーザーの位置情報のデータは、skmob.preprocessing.detection.stay_locations関数で滞在判定を行った結果(stdf)を利用します。
tdf_dist = stdf.copy()
# 距離測定用前処理
tdf_dist['経度緯度'] = tdf_dist.apply(lambda x: Point(x['lng'], x['lat']), axis=1)
# 距離測定
tdf_dist['最寄駅'] = [calc_dist(stay_loc, tdf_sta, geometry_col='geometry')[0] for stay_loc in tdf_dist['経度緯度']]
tdf_dist['最寄駅距離'] = [calc_dist(stay_loc, tdf_sta, geometry_col='geometry')[1] for stay_loc in tdf_dist['経度緯度']]
# 滞在判定
cf_stay_dist = 200 # m
tdf_dist['滞在判定'] = tdf_dist['最寄駅距離'] < cf_stay_disttdf_distの結果を下表にまとめます。
ユーザーの滞在地点ごとに、どこかの駅に滞在しているのか否か、駅名と距離をまとめています。
表 ユーザーの滞在地点ごとの最寄駅と距離、滞在判定結果
| datetime | leaving_datetime | 経度緯度 | 最寄駅 | 最寄駅距離 | 滞在判定 | |
| 0 | 2024/11/9 9:45:00 | 2024/11/9 10:03:12 | POINT (139.7023 35.6593) | 渋谷 | 146.5 | TRUE |
| 1 | 2024/11/9 11:05:56 | 2024/11/9 11:20:15 | POINT (139.702 35.6594) | 渋谷 | 148.5 | TRUE |
| 2 | 2024/11/9 11:23:38 | 2024/11/9 11:53:00 | POINT (139.7593 35.6667) | 新橋 | 105.4 | TRUE |
滞在地点の可視化
最後に、結果を地図上にマッピングして滞在地点(駅)を正しく判定できているかを確認します。
次の地図は、地図上に山手線駅の鉄道駅(青丸)とユーザーの滞在地点(赤丸)をマッピングしたものです。
丸の半径は200mであり、鉄道駅の半径200m以内の位置にユーザーが滞在していれば、当該駅に滞在したと判定されます。
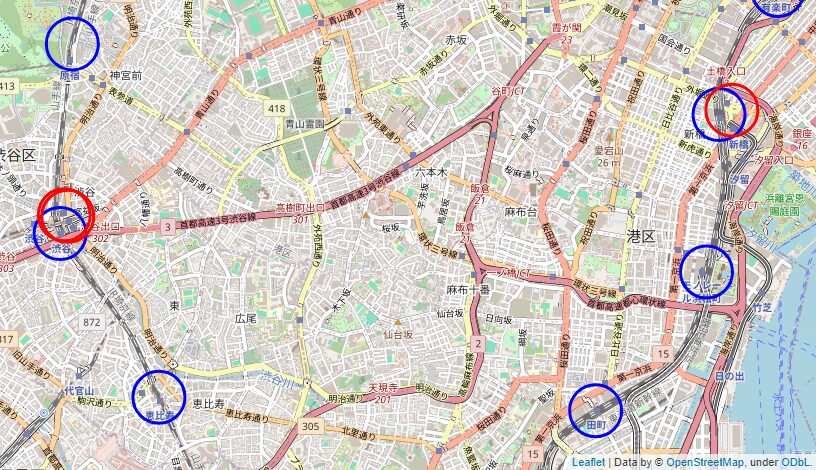
この例では、西側の渋谷駅と東側の新橋駅で青丸と赤丸が重なっている場所があります。
このため、渋谷駅と新橋駅の両駅をユーザーが滞在したことがわかります。
滞在判定のコードを以下に示します。
# 関数定義:foliumで地図上に位置情報をプロット(iterrows)
def mapping(df_loc, df_spot):
'''
df_loc: DataFrame, 位置情報
df_spot: DataFrame, スポットの位置座標
'''
# foliumで地図を表示
# デフォルトの中心とズーム
default_location = [df_loc['lat'].mean(), df_loc['lng'].mean()]
default_zomm = 12
folium_map = folium.Map(location=default_location, zoom_start=default_zomm)
# スポット情報をプロット
for idx, row in df_spot.iterrows():
folium.Circle(
location=[row['lat'], row['lng']],
popup=row['駅名'],
color='blue',
radius=200,
).add_to(folium_map)
# 位置情報をプロット
for idx, row in df_loc.iterrows():
folium.Circle(
location=[row['lat'], row['lng']],
popup=row['datetime'],
color = 'red',
radius=200, # マーカーサイズを指定
).add_to(folium_map)
return folium_map
# 地図上に位置情報をマッピング
folium_map = mapping(df_loc=tdf_dist, df_spot=tdf_sta)
display(folium_map)参考文献
scikit-mobility documentation, scikit-mobility 2024/12/8閲覧
GPS2CSV App Store 2024/11/8閲覧
鉄道時系列データ 国土数値情報 2024/12/8閲覧
Folium 0.18.0 documentation, folium 2024/11/18閲覧
foliumの基本的な使い方とオープンデータ活用 Qiita 2024/11/18閲覧