線形回帰を行う手法の1つとして正規方程式を用いる方法があります。
正規方程式を解くことで、最も当てはまりのよい回帰直線を求めることができるため、線形回帰のアプローチとして用いられています。
このページでは、正規方程式を用いた線形回帰について解説します。
正規方程式とは
正規方程式(normal equation)とは、線形回帰において損失関数(実測値と推定値の誤差の平均二乗誤差(MSE, Mean Squared Error))が最小になる回帰直線を求めるための方程式です。
正規方程式を解くことでデータに対して最も当てはまりの良い回帰直線を引くことができます。
以下では、正規方程式を使って線形回帰を行う方法を解説します。
線形モデル
1変数の直線は次のように表せます。
$$ f(x) = θ_0 + θ_1 x $$
ここで、$ θ_0 $ は切片、$ θ_1 $ は傾きです。
簡略化のために1変数( $ x $ )のみを扱います。
線形回帰における損失関数
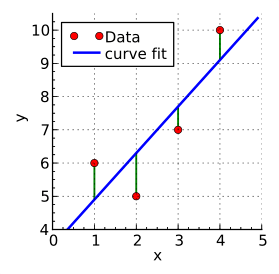
線形回帰では、実測値(観測データ)と推計値(線形回帰による予測値)の差分(誤差)が最小になるような回帰直線を求めます。
誤差の評価には平均二乗誤差(MSE, Mean Squared Error)を使用します。
実測値(実データ)を $ y_i $ 、線形回帰による推定値 $ \widehat{ y_i } = θ_0 + θ_1 x_i $ とすると、MSEは次のように表されます。
$$ MSE = \frac{ 1 } { n } \displaystyle \sum_{ i=1 }^n \{ y_i - \widehat{ y_i } \}^2 = \frac{ 1 } { n } \displaystyle \sum_{ i=1 }^n \{ y_i - (θ_0 + θ_1 x_i) \}^2 $$
ここで $ n $ は実測値の個数です。
このMSEは全データの誤差を積算しており、MSEが最小(=全体の誤差が最小)になるような回帰直線を求めればよいということです。
そこで、今回はMSEを損失関数 $ L (θ_0, θ_1) $ として利用して回帰直線を求めます。
$$ L (θ_0, θ_1) = MSE $$
$ L $ のパラメータが $ θ_0 $ と $ θ_1 $ なのは、これらが求めたい回帰直線の切片と傾きであるからです。
線形回帰による推定値
線形回帰による推定値 $ \widehat{ y_i } $ は $ θ_0, θ_1, x_i $ を使って次のように表せます。
$$ \widehat{ y_i } = θ_0 + θ_1 x_i $$
この関係は全ての実測データに対する推定値について成り立つので、連立方程式として書くと次のように表せます。
$$ \widehat{ y_1 } = θ_{ 10 } + θ_{ 11 } x_{ 11 } $$
$$ \widehat{ y_2 } = θ_{ 20 } + θ_{ 21 } x_{ 21 } $$
$$ \cdots $$
$$ \widehat{ y_n } = θ_{ n0 } + θ_{ n1 } x_{ n1 } $$
さらに、これらの連立方程式を行列と見立て、右辺を $ x $ と $ θ $ の行列の積に分解します。
$$ \begin{equation}
\begin{bmatrix}
\widehat{ y_1 } \\
\widehat{ y_2 } \\
\cdots \\
\widehat{ y_n }
\end{bmatrix}
=
\begin{bmatrix}
1 & x_{ 11 } \\
1 & x_{ 21 } \\
\cdots & \cdots \\
1 & x_{ n1 } \\
\end{bmatrix}
\begin{bmatrix}
θ_0 \\
θ_1 \\
\cdots \\
θ_n \\
\end{bmatrix}
\end{equation} $$
個々の行列やベクトルを記号で表記しては次のように表します。
$$ \widehat{ y } = \mathbf{ X } θ $$
回帰直線の導出
次に損失関数の最小値を求めます。
実測値と推定値の誤差をMSEで評価する場合、損失関数 $ L $ は以下のように表せます。
$$ L = MSE = \frac{ 1 } { n } \displaystyle \sum_{ i=1 }^n \{ y_i -\widehat{ y_i } \}^2 $$
この方程式の右辺を変形して正規方程式を導出します。
はじめに、上式の右辺に $ \widehat{ y } = \mathbf{ X } θ $ を代入します。
$$ L (θ) = \frac{ 1 } { n } \displaystyle \sum_{ i=1 }^n \{ y_i - \mathbf{ X } θ \}^2 $$
ここで二乗和は転置行列と元の行列の積として表せることから、以下のように変形できます。
$$ L (θ) = \frac{ 1 } { n } ( y - \mathbf{ X } θ )^T ( y - \mathbf{ X } θ ) $$
転置行列と元の行列の積を展開して整理します。
展開した結果出てくる2つの項 $ - y^T \mathbf{ X } θ $ と $ - θ^T \mathbf{ X }^T y $ は、いずれも行列の積を取るとスカラーになります(各行列のサイズ( $ m \times n $ )からわかる)。
スカラーであれば転置しても同じ値であり、いずれも $ -θ^T \mathbf{ X }^T y $ と表記できることから次のようにまとめます。
$$ L (θ) = \frac{ 1 } { n } ( y^T y - 2 θ^T \mathbf{ X }^T y + θ^T \mathbf{ X }^T \mathbf{ X } θ ) $$
損失関数が最小値にはなるのは、$ L $ の $ θ $ での偏微分がゼロになるときです。
これに対応するのは、上式の右辺を $ θ $ で偏微分した値がゼロに等しいときです。
$$ -2 \mathbf{ X }^T y = 2 \mathbf{ X }^T \mathbf{ X } θ = 0 $$
さらに $ θ $ の式に変形します。
$$ θ = ( \mathbf{ X }^T \mathbf{ X } )^{ -1 } \mathbf{ X }^T y $$
この方程式を正規方程式とよびます。
この式を解くことで、最も当てはまりのよい回帰直線(の切片と傾き)を求めることができます。
参考文献
Ordinary least squares, Wikipedia 2024/1/15閲覧
正規方程式を完全解説(導出あり)【機械学習入門4】 米国データサイエンティストのブログ 2024/1/21閲覧
正規方程式(normal equation)の導出と直感的理解 あつまれ統計の森 2024/1/21閲覧