コンピュータ上で文書ファイルを開く際に文字コードを正しく指定しないと文字化けして文字が読めない状態になります。
このページでは、文字コードとは何かと代表的な文字コード(ASCII, Shift-JIS, Unicode, UTF-8)について解説します。
文字コードとは
文字コードとは、コンピュータ上で扱いたい文字について、文字の種類ごとに1つの識別番号を割り振り、文字を数字として扱えるようにしたものです。
コンピュータが扱うあらゆるデータは0/1の二進数で表されるため、1~数バイト分の数字で1文字を表現します。
英語のアルファベットであれば大文字小文字合わせても52文字で済みますが、日本語や中国語では膨大な種類の漢字があるため、1文字を表現するためにはより多くの桁数の数字が必要になります。
文字コードは文字をコンピュータ上で扱う際の文字と識別番号の対応表(の体系)であるため、同じ日本語のひらがなを表現する際にも、割り当て方法が異なる複数の文字コードが存在します。
文字コードの種類
文字コードは歴史的経緯により複数の種類の文字コードが使われてきました。
1963年にアメリカで制定されたASCII (American Standard Code for Information Interchange)は、アメリカで使われる(=英語で使う)アルファベットやアラビア数字、制御文字(Nullや改行コードなど)を対象とした文字コードです。
英語以外の言語での使用を想定していなかったため、ASCIIをベースとして他言語の文字も扱えるようにした派生規格が複数誕生し、文字コードを正しく指定しないと文字化けをするといった問題も発生しました。
1980年代にマイクロソフトによって設計されたシフトJIS(Shift-JIS, SJIS)は、コンピュータ上で日本語を扱うために開発された文字コードです。
従来の文字コードでは、エスケープシーケンスとよばれる特別な文字を挿入することで、それ以降の文字を解読する文字コードを指定します。
一方、シフトJISではひらがなや漢字といった文字の分類ごとにまとまった識別番号を割り当てるのが特徴です。
そのため、シフトJISではエスケープシーケンスを挿入しなくても、多くの文字を扱うことができます。
英語と日本語に限らず、全世界で使われる文字を対象とした文字コードがUnicodeです。
Unicodeでは、基本的な文字や記号は2バイト(16進数4桁)で表現され、U+0000やU+9FFFなどと表現します。
Unicodeにおいて、全ての文字を2バイトで表現するのは非効率なので、使用頻度が高い文字をできるだけ短い桁数で表現できるように改良したのがUTF-8です。
UTF-8では、1文字を可変長で表現しています。
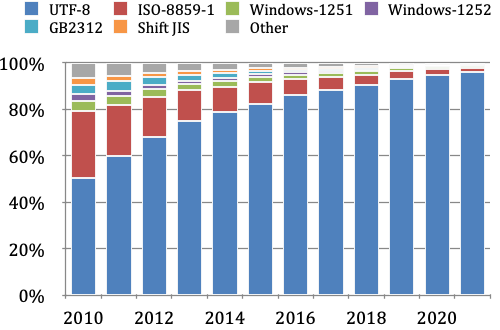
現在(2024年)では、文字コードの国際標準はUnicodeとなっており、UTF-8を使用するのが一般的です。
しかし、一部UTF-8がデフォルトになっていないサービスも存在します。
たとえば、Microsoft ExcelはCSVファイルをシフトJISで開こうとするため、事前にファイルの文字コードを変換しておく必要があります。
正規表現による文字種指定
プログラミング言語で文字列中から「ひらがな」や「カタカナ」、「漢字」などの文字種を抽出する際には、正規表現を使用します。
正規表現で文字種を指定する際には、文字コードの並び順で最初と最後の文字を使って指定します。
たとえば、半角アラビア数字あれば文字コード上の並び順は「0123456789」となるので最初の「0」と最後の「9」を使って ” [0-9]* " といった形式で指定します(" * " は直前の文字を0回以上繰り返す)。
そのため、正確に文字種を網羅する記述をするためには、文字コードの並び順を知っておく必要があります。
詳細については次のページで解説しています。
-

参考正規表現による文字指定(Unicodeの並び順に則した指定)
正規表現を使用して数字やカタカナなどを文字種を指定する際には、文字コードの並びの最初と最後の文字を使って「0-9」といった指定の仕方をします。このページでは、ひらがなやカタカナといった文字種ごとに並び ...
続きを見る

参考文献
黒橋 禎夫「自然言語処理[三訂版]」一般財団法人 放送大学教育振興会 (2023)
ASCII ウィキペディア 2024/9/16閲覧
Shift_JIS ウィキペディア 2024/9/16閲覧
Unicode ウィキペディア 2024/9/16閲覧
アドビ株式会社 山本 太郎「文字コード技術部会」文字情報技術促進協議会 2024/9/16閲覧
Pythonの正規表現で漢字・ひらがな・カタカナ・英数字を判定・抽出・カウント nkmk note 2024/9/16閲覧